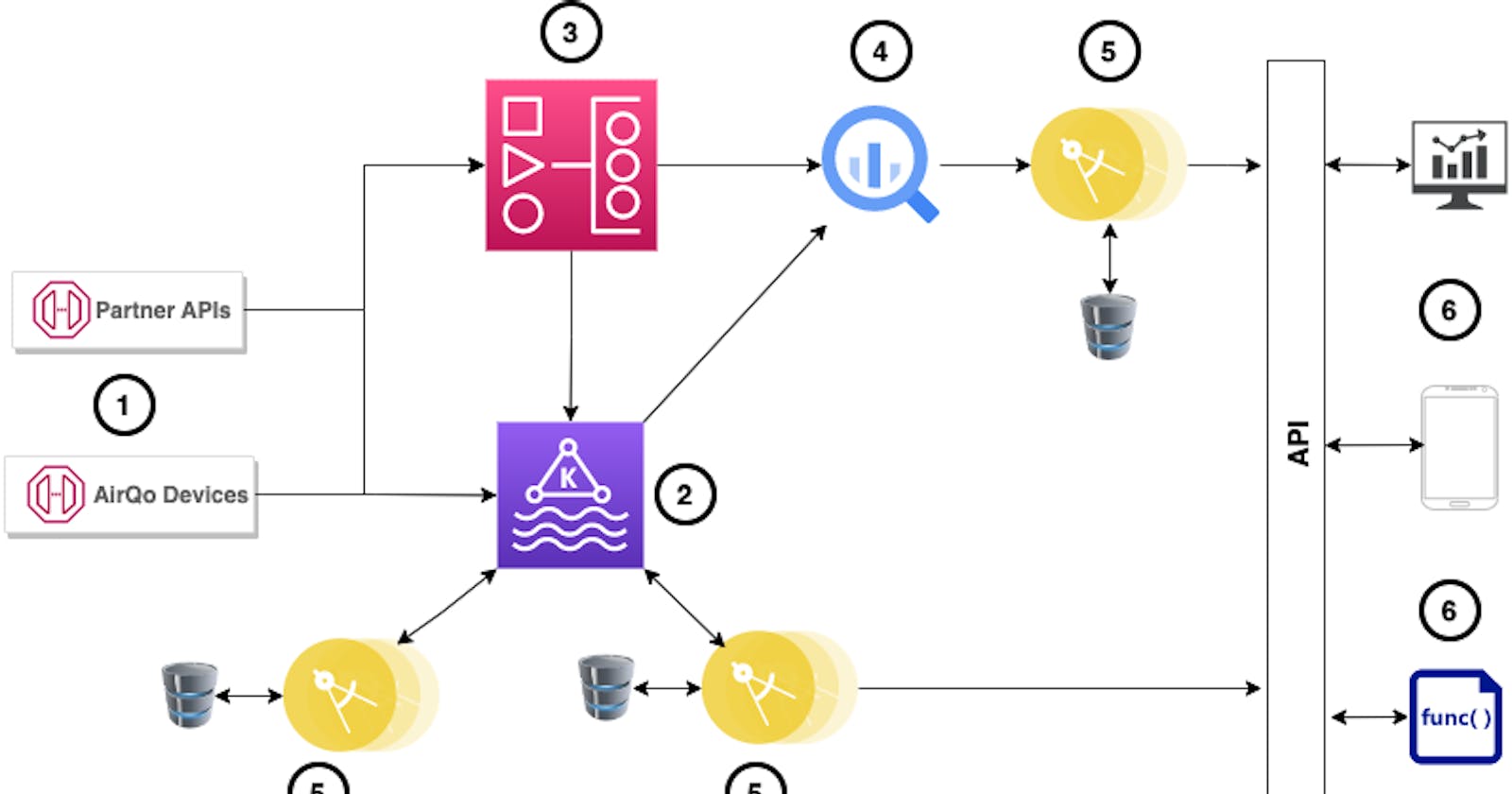


Picture above shows a subset of AirQo’s architecture reflecting information flow between microservices.
AirQo’s microservices architecture comprises multiple domain-specific applications, each with a distinct role in the processing of air quality data and information. The minute-based streaming of data from AirQo sensors and partner organizations creates the urge to make data available for the microservices which perform vigorous tasks such as calibration, predicting air quality, detecting faults, etc. This vast interconnection between application and data, with some applications depending on the output data from other applications, raises a lot of issues but is not limited to:
- Failure of a microservice: The high level of decoupling enforced in our microservices architecture does not guarantee that every microservice will perform its duties successfully or process all the data it is expected to process at any given time. Failure of a microservice on which other microservices depend for preprocessed data can cause a lag in the pipeline and hence a lot of data is lost if not addressed on time. Data insufficiency makes it difficult for both human beings and machine learning applications to make informed decisions.
- Service Monitoring and performance: Service monitoring and performance tracing in microservices data pipelines can be complicated especially in such a case where we have multiple decoupled applications and data pipelines with data dependencies on each other. How would you know that a core microservice has malfunctioned ?, How would you tell that a particular stage of the pipeline is broken?. You can only improve on something you have prior information about.
- Data inconsistency: The one-to-many relationship between the data and microservices creates room for data inconsistency across the microservices, causing information mismatch on our digital platforms and access points.
Some of the tools and technologies we have applied to solve those problems include;
A. Streaming and Workflow management
We rely on two open-source tools Airflow and Kafka for streaming and pipeline management.
Airflow
Airflow is an open-source workflow management platform for data pipelines. With the various pipelines working on ensuring data availability, airflow helps in scheduling tasks based on our configurations and provides insights into the status of the pipelines and data flow throughout its journey to our digital platforms.
Kafka
We use Kafka, an open-source distributed event store and stream-processing platform to handle real-time air quality data sourced from the AirQo sensors and partner organizations. It enables the streaming of huge amounts of data with the advantage of intermediate data storage between services. In case a microservice is not available at any particular time and some data is not processed, the unprocessed data can be stored on Kafka topics and processed as soon as the service gets online. This ensures we don’t lose out on any data due to service unavailability.
This high-throughput and low-latency of Kafka enables us to have the same copy of data existing on different microservices, reducing data inconsistency.
B. CI/CD and Service monitoring
We leverage Kubernetes and GitHub actions to ensure continuous deployment of applications as soon as they are ready. This helps to reduce the time we spend on deploying applications.
Monitoring is done with the help of Grafana and Prometheus, which send alerts to our communication channels in case there is a malfunction of any microservice.
We depend on Istio, an open-source service Mesh, to provide a stable communication channel between the microservices, especially in cases where Kafka is not a suitable solution.
C. Data Storage
Our data storage units have been set up and configured to support handling vast amounts of data while putting into consideration cost and performance issues. We use BigQuery as our data warehouse with tables clustered and partitioned. The microservices store data using a database-per-service approach and rely on PostgreSQL and Mongo depending on the use case.
Explore our digital tools. Learn about the quality of air around you. Click here to get started.
